Image

NCC Bulgaria presents the success story
NCC Bulgaria was founded by the Institute of Information and Communication Technologies at the Bulgarian Academy of Sciences, Sofia University “St. Kliment Ohridski”, and the University of National and World Economy.
NCC Bulgaria is focused on:
Creating a roadmap for successful work in the field of HPC, big data analysis, and AI;
Analyzing the existing competencies and facilitating the use of HPC/HPDA/AI in Bulgaria;
Raising awareness and promoting HPC/HPDA/AI use in companies and the public sector.
Scientific/governmental/private partners involved:
Commercial banks operate within a highly regulated and security-sensitive environment. These institutions offer a wide range of financial services and manage large volumes of sensitive customer and transactional data. With a strong focus on digital transformation, banks continually invest in modernising their infrastructure, enhancing cybersecurity capabilities, and adopting privacy-preserving technologies. Their commitment to operational resilience, GDPR compliance, and risk-aware data governance makes them an ideal partner for implementing and validating an advanced, dual-layer monitoring solution supported by high-performance data analytics.
Technical/Scientific Challenge:
It has been clearly established that multiple cybersecurity challenges persist in environments where digital complexity, high data velocity, and operational interconnectivity dominate. Delayed detection of suspicious activities often results from fragmented logging mechanisms and disconnected monitoring systems, making real-time threat identification difficult. The absence of a unified framework for classifying alerts, events, and incidents across both network and application layers leads to inconsistent responses and misaligned priorities. In high-throughput systems driven by Big Data, log volumes are massive, frequently inconsistent, and often lack centralized validation, which undermines the quality and trustworthiness of security intelligence. Visibility into anomalies, user behaviour patterns, and data integrity breaches remains limited, especially in dynamic operational settings. These challenges are further intensified by the pressing need for auditability, regulatory alignment (e.g., GDPR), and continuous operational assurance. Addressing these issues requires scalable and integrated approaches built upon HPC to enable automated event processing, real-time anomaly detection, and continuous data quality validation across both SIEM and Log Manager systems.
Key Technical Challenges:
The in-depth assessment of the security monitoring environment uncovered a set of complex and interconnected technical challenges that directly impacted the organization’s ability to detect, classify, and respond to threats in a timely and reliable manner. These challenges span across data collection, quality assurance, event correlation, and system scalability. Their resolution is critical to achieving reliable, real-time cybersecurity intelligence. Below is a breakdown of the most pressing issues:
Fragmented Logging Infrastructure: Log data was being generated by multiple, heterogeneous sources, including firewalls, intrusion detection systems, application servers, user authentication platforms, and databases - each producing logs in different formats, using inconsistent timestamp resolutions, and lacking standard field structures. Without a centralized ingestion or normalization mechanism, this fragmentation led to delays in analysis, loss of contextual information, and gaps in cross-system correlation, ultimately limiting the visibility needed for effective threat detection.
Lack of Unified Event and Incident Classification: There was no standardized framework for classifying logs as alerts, events, or confirmed incidents across network and application layers. Network-level security was handled through SIEM systems, while application and system-level events were managed separately using Log Manager solutions. The absence of integration between these tools led to discrepancies in severity assessment, unclear ownership of alerts, and inefficient incident triage workflows.
Inconsistent and Low-Quality Log Data: Log records frequently contained missing values, malformed fields, duplicated or misaligned timestamps, and a lack of structure. These inconsistencies made it difficult to rely on log data for security investigations, compliance reporting, or audit purposes. Furthermore, no automated validation mechanisms were in place to assess the accuracy, completeness, or freshness of the data, leaving quality assurance entirely dependent on manual review.
High Volume and Velocity of Log Streams: The infrastructure produced enormous volumes of logs per minute - from transactional APIs, security sensors, and operational systems, far exceeding the capacity of manual inspection or traditional sequential processing. Without access to High-Performance Computing (HPC) capabilities or scalable High-Performance Data Analytics (HPDA) tools, real-time analysis of this data was impractical, resulting in missed threats and delayed response times.
Absence of Real-Time, Behavior-Based Anomaly Detection: Security systems relied heavily on predefined rules and static thresholds to trigger alerts, without the ability to analyze cross-layer behavior or detect subtle anomalies over time. There was no mechanism for learning from historical incidents or adapting detection logic based on evolving attack patterns, leaving the environment vulnerable to unknown or low-and-slow threat vectors.
Limited Auditability and Incident Traceability: Due to the distributed nature of the logging ecosystem and lack of standardized metadata, it was difficult to reconstruct complete incident timelines or determine the root cause of complex security events. The inability to track the lifecycle of an alert - from detection to resolution - posed serious risks for regulatory compliance and undermined the effectiveness of post-incident review processes.
Solutions:
To address the identified technical challenges, a comprehensive and scalable cybersecurity monitoring solution was developed through the strategic integration of Security Information and Event Management (SIEM) and Log Manager systems. This dual-layered architecture was designed to ensure visibility across both network and application domains while maintaining scalability, data quality, and compliance. The entire system is orchestrated under a centralized risk governance layer, providing consistent and traceable security intelligence. At the core of the solution lies a coordinated architecture, illustrated in Figure 1.
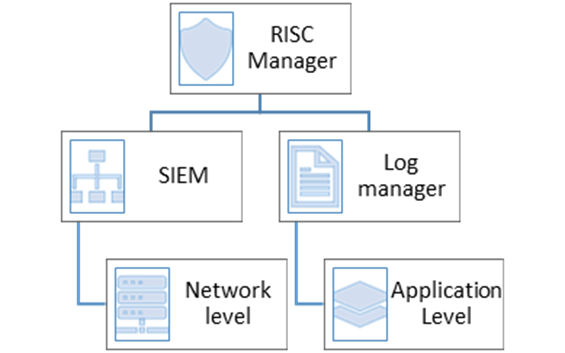
As illustrated in Figure 1, the RISC Manager is the central unit responsible for managing, correlating, and interpreting data collected from both the network and application environments. The model is divided into two main operational layers:
The SIEM system is responsible for capturing and analysing events at the network level, including firewall activity, intrusion detection alerts, and endpoint security logs. It enables real-time threat detection, rule-based correlation, and behavioural analysis of suspicious activities across infrastructure components.
The Log Manager processes logs at the application level, aggregating data from APIs, transactional services, backend systems, and operational workflows. This provides deep insights into system behavior, business logic anomalies, fraud detection scenarios, and usage patterns critical for application-layer security.
To unify the outputs of both layers, a standardized event classification model was introduced. All security-related data is now categorized as alerts, events, or confirmed incidents, providing a consistent and structured language for threat detection, triage, and response across teams and systems. In this model:
An event refers to any system or user activity captured in the logs - such as a login attempt, file access, or configuration change — which is recorded for monitoring, auditing, or analytical purposes. Not all events indicate risk, but they provide critical context for understanding baseline activity.
An alert is a notification automatically generated when an event (or combination of events) matches predefined rules or behavior-based thresholds. Alerts serve as early warning signals of potentially suspicious activity and require review by security personnel.
An incident is a verified or strongly suspected breach, violation, or compromise, either confirmed through analysis or triggered by correlating multiple alerts. Incidents represent high-priority cases that demand investigation, response, and documentation.
This harmonized taxonomy improves triage accuracy, reduces alert fatigue, and ensures alignment across security and operational teams, especially in high-pressure environments where timely and consistent decision-making is critical.
To ensure the reliability of the collected log data, Python-based validation pipelines were implemented. Using Amazon Deequ, quality constraints were applied to assess the accuracy, completeness, and timeliness of incoming log entries. These checks automatically flagged malformed fields, missing timestamps, and inconsistent record formats across both SIEM and Log Manager streams. For scalability and near real-time execution, the solution was integrated with Apache Spark, allowing validation jobs to run continuously over millions of entries without performance degradation.
In accordance with data protection regulations such as GDPR, a robust set of anonymization and privacy-by-design mechanisms was embedded directly into the log processing pipeline. These mechanisms ensured that sensitive user and system identifiers were protected at all stages - from data ingestion to storage and analysis. Practically, the solution applied multiple anonymization methods, implemented through Python-based scripts and configurable pipelines, depending on the nature and usage of the data:
Masking was used to partially hide sensitive fields such as card numbers or email addresses. Maintaining context without revealing identity.
Hashing was applied to values like identification numbers for users, sessions, and IP addresses, rendering them irreversible while still allowing matching across logs. This enabled pattern tracking (e.g., frequency of suspicious sessions) without compromising user identity.
Tokenization was implemented for account numbers, where reversibility was needed in specific contexts (e.g., post-incident investigation with authorized access). Tokens were managed securely and could be resolved only through controlled mechanisms.
Differential privacy was introduced in the analysis layer, especially in dashboards showing behavioural trends. For example, API usage patterns were aggregated with calibrated noise, ensuring that individual user behaviours could not be isolated, while still revealing broader trends such as “suspicious POST requests per endpoint.”
Dynamic field suppression logic was used in compliance views, where logs destined for audit reports automatically excluded fields exceeding the predefined data exposure threshold (e.g., location granularity, user-agent strings).
K-anonymity was applied to ensure that each record is indistinguishable from at least k–1 others within the dataset, minimizing re-identification risk while preserving group-level analysis.
L-diversity enhanced the protection by requiring diversity in sensitive attributes across anonymised groups, preventing inference attacks even in overlapping datasets.
The solution was implemented using open-source and scalable technologies, including Python, Apache Spark, and privacy-preserving algorithms based on k-anonymity, l-diversity, and differential privacy.
Scientific impact:
Cross-layer log intelligence modelling:
The solution introduces a scientifically structured approach to unifying network-level and application-level log data into a single, interpretable model. This cross-layer intelligence framework contributes to cybersecurity research by enabling consistent incident classification and structured analytics.
Event taxonomy for reproducible triage workflows:
The formal definition of event, alert, and incident establishes a reusable taxonomy that enhances clarity, traceability, and reproducibility in security operations - supporting academic efforts in standardizing security response frameworks.
Automated data quality validation methodology:
By applying rule-based tools like Python Deequ for validating log completeness, accuracy, and timeliness, the project contributes to ongoing research in data quality management for cybersecurity analytics.
Operational use of privacy-preserving methods:
The deployment of anonymization techniques such as hashing, masking, tokenization, and differential privacy within a live system bridges theoretical privacy models with practical, GDPR-compliant implementation.
Scalable security analytics using HPC:
The integration of high-performance computing and data analytics for near real-time processing of massive log volumes showcases how scientific computing resources can enhance cybersecurity systems in complex, data-intensive environments.
Foundation for further research in adaptive detection models:
The solution provides a practical base for future experimentation in behaviour-based anomaly detection, log enrichment, and AI-driven response strategies within monitored environments.
Benefits:
Faster threat detection and response: The integrated monitoring model enabled security teams to identify and respond to incidents more quickly by correlating data from both network and application layers in real time.
Improved incident classification and triage efficiency: The standardized classification model (event → alert → incident) helped reduce false positives, prioritize real risks, and streamline collaboration between IT and security teams.
Higher data quality and trust in log analysis: Automated validation processes ensured that logs used for decision-making were accurate, complete, and timely, increasing the reliability of investigations and reports.
Full traceability and audit readiness: By maintaining structured and anonymized logs with validation checkpoints, the system supports clear, end-to-end traceability of incidents, aligned with audit and compliance requirements.
Privacy-compliant monitoring processes: Sensitive data within logs was protected using hashing, masking, tokenization, and differential privacy, ensuring GDPR compliance without compromising analytical utility.
Scalable processing of high-volume log data: Leveraging HPC and HPDA technologies allowed the system to handle millions of log records per hour, supporting growth without degradation in performance.
Enhanced visibility into system behavior and usage patterns: Dashboards and visualizations provided operational teams with actionable insights into API behavior, user activity, and infrastructure health.
Success story # Highlights:
A dual-layer monitoring model was implemented, combining SIEM for network-level security and Log Manager for application-layer oversight under a centralized coordination strategy (RISC-Guided Log Intelligence Model).
A standardized classification system was adopted, clearly distinguishing between events, alerts, and incidents, resulting in improved triage and cross-team communication.
Python-based log validation mechanisms were introduced, achieving over 95% accuracy and completeness in real-time log streams using automated data quality checks.
Anonymization techniques such as masking, hashing, tokenization, and differential privacy were applied across the log pipeline, ensuring full GDPR compliance without sacrificing analytical depth.
High-Performance Computing (HPC) and High-Performance Data Analytics (HPDA) capabilities enabled the processing of millions of log entries per hour, with no performance degradation.
Real-time alerting and dynamic dashboards provided both security and operational teams with actionable visibility into user activity, API behavior, and system anomalies.
The solution is scalable, transferable, and replicable across other institutions with high log volumes and cybersecurity requirements.
Contact:
- Prof. Kamelia Stefanova, kstefanova[at]unwe.bg, University of National and World Economy, Sofia, Bulgaria
- Prof. Valentin Kisimov, vkisimov[at]unwe.bg, University of National and World Economy, Sofia, Bulgaria
- Dr. Ivona Velkova, ivonavelkova[at]unwe.bg, University of National and World Economy, Sofia, Bulgaria