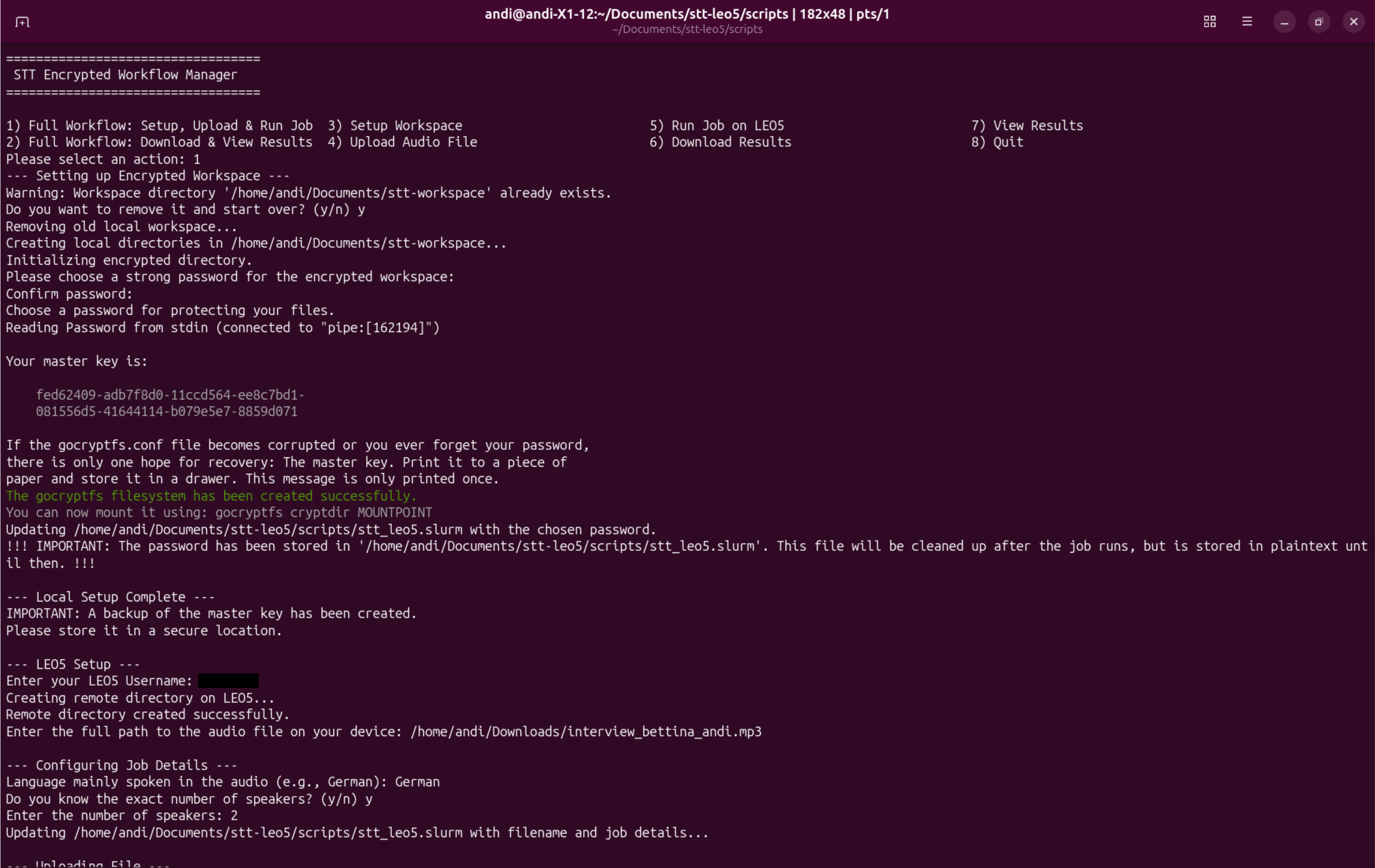
Image
To keep sensitive interview recordings out of third‑party clouds, the University of Innsbruck now uses an AI-based speech‑to‑text tool developed within the EuroCC project that runs locally on the LEO5 HPC system and ensures full data sovereignty.
The Challenge
In political science, interviews are often the method of choice for collecting research data. However, manually transcribing recordings is both time-consuming and costly. As a result, many researchers now rely on AI-based transcription tools. “Automatically generated transcripts are everywhere these days – even if the quality is not always convincing,” says Professor Franz Eder, political scientist at the University of Innsbruck (UIBK). “That made me wonder: can we do better – and, above all, can we run it locally on our own servers so that the data stays in-house?”
To answer this question, Andreas Lindner joined the project. He specialises in deploying AI models efficiently on HPC systems. The project also received support from the HPC team of the Central IT Services (ZID) and the university’s research focus area Scientific Computing.
The Solution
The solution needed to be powerful enough to run modern AI models, operate entirely on local infrastructure, and give the university full control over processes and data. These core requirements were quickly met. However, as discussions with users progressed, expectations grew step by step: speakers had to be identifiable, timestamps inserted, and translations into other languages enabled. What began as a small assignment evolved into a sophisticated project combining advanced features, computational efficiency and digital sovereignty.
Today, the tool follows a clearly defined workflow spanning a Linux workstation and the local HPC system LEO5. After an audio file is transferred from a workstation at the Office for Open Science within the Faculty of Social and Political Sciences to the university’s supercomputer, the audio is analysed and segmented by speaker. The tool then automatically transcribes each segment. If required, the completed transcript can subsequently be translated into other languages.
The technology behind it
The AI solution deliberately builds on established, well-documented components, which Andreas Lindner specifically adapted for use on LEO5:
- Transcription is performed using a Whisper model: https://huggingface.co/docs/transformers/en/model_doc/whisper
- Speaker diarisation – the process of assigning speech segments and timestamps to individual speakers – is handled by models from pyannote: https://huggingface.co/pyannote
- Translation of transcripts is carried out using a Tower model developed by Unbabel: https://huggingface.co/collections/Unbabel/tower
- Data encryption and decryption are implemented using gocryptfs, ensuring secure handling of sensitive information: https://www.baeldung.com/linux/gocryptfs-encrypt-decrypt-dirs
- To guarantee a clearly separated and reproducible runtime environment on LEO5, the speech-to-text workflow runs inside a software container.
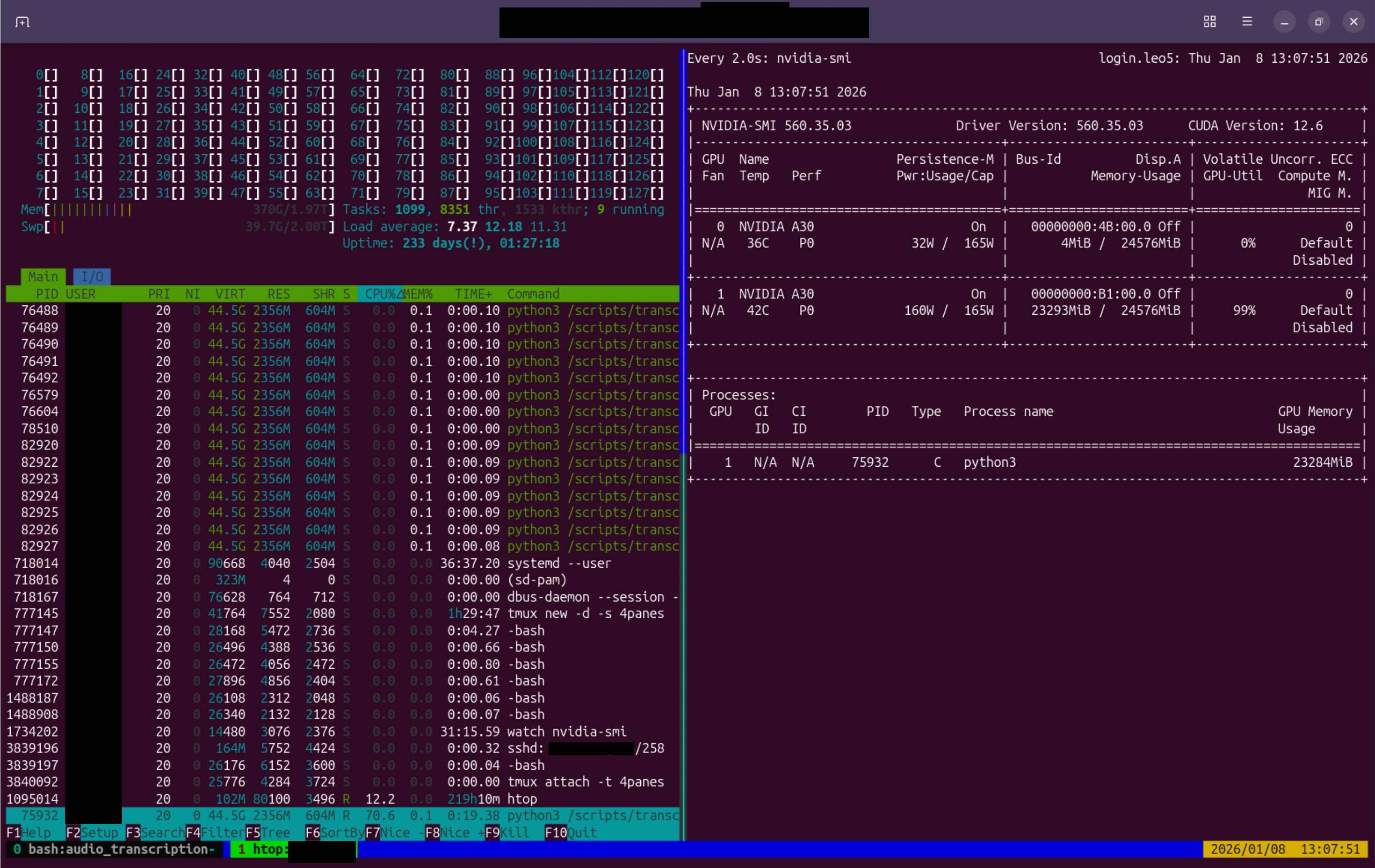
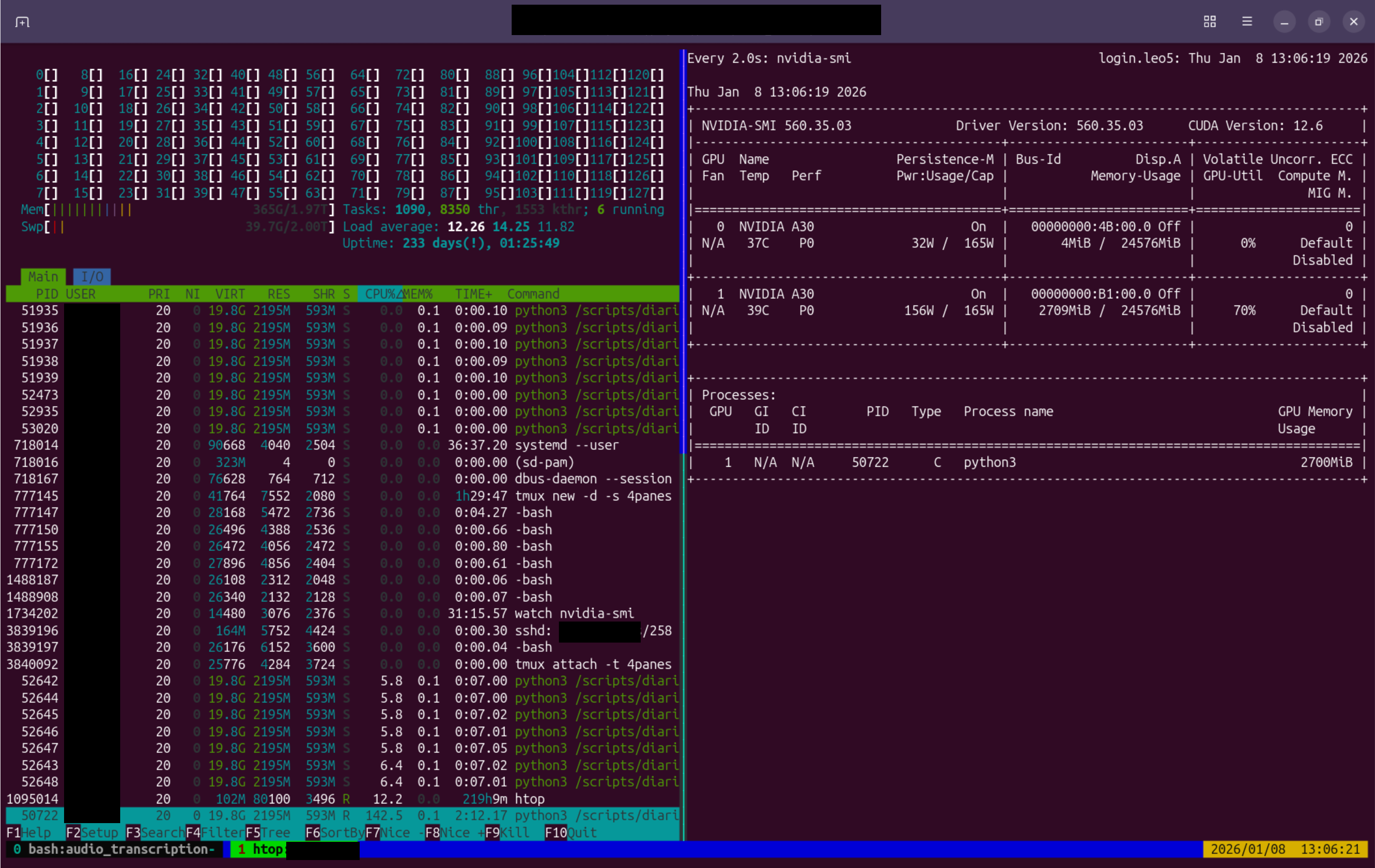
The Outcome
The solution is now technically operational and fully documented. It integrates into the existing research infrastructure, relieves researchers of the time-intensive transcription process, and safeguards data sovereignty. AI Factory Austria (AI:AT) uses the tool internally to transcribe video conferences. Incidentally, the interview with Andreas Lindner on which this article is based was itself transcribed using the new tool on LEO5.
An additional benefit of the system is that transcription tasks are not time-critical. They are automatically scheduled into computational gaps between other projects. This improves utilisation of the HPC systems, which consume power even when idle. By putting otherwise unused capacity to productive use, overall energy efficiency increases.
With this new tool, the Faculty of Social and Political Sciences now has access to an AI-supported solution that simplifies research workflows, preserves data sovereignty, and demonstrates how modern technology can be deployed responsibly.
Dataset now publicly available
Since automated transcription is needed not only in Innsbruck but in many other institutions, Andreas Lindner has made the corresponding GitLab repository publicly available. It may therefore also be useful for other operators of high-performance computing clusters who wish to implement a similar setup:
https://researchdata.uibk.ac.at/records/z877w-c6110
https://doi.org/10.24433/CO.0416787.v1
For more info on this case and on HPC in general please contact info@eurocc-austria.at.